
This post serves as a report from my attendance to Kubecon and CloudNativeCon 2023 Europe that took place in
Amsterdam in April 2023. It was my second time physically attending this conference, the first one was in
Austin, Texas (USA) in 2017. I also attended once in a virtual fashion.
The content here is mostly generated for the sake of my own recollection and learnings, and is written from
the notes I took during the event.
The very first session was the opening keynote, which reunited the whole crowd to bootstrap the event and
share the excitement about the days ahead. Some astonishing numbers were announced: there were more than
10.000 people attending, and apparently it could confidently be said that it was the largest open source
technology conference taking place in Europe in recent times.
It was also communicated that the next couple iteration of the event will be run in China in September 2023
and Paris in March 2024.
More numbers, the CNCF was hosting about 159 projects, involving 1300 maintainers and about 200.000
contributors. The cloud-native community is ever-increasing, and there seems to be a strong trend in the
industry for cloud-native technology adoption and all-things related to PaaS and IaaS.
The event program had different tracks, and in each one there was an interesting mix of low-level and higher
level talks for a variety of audience. On many occasions I found that reading the talk title alone was not
enough to know in advance if a talk was a 101 kind of thing or for experienced engineers. But unlike in
previous editions, I didn t have the feeling that the purpose of the conference was to try selling me
anything. Obviously, speakers would make sure to mention, or highlight in a subtle way, the involvement of a
given company in a given solution or piece of the ecosystem. But it was non-invasive and fair enough for me.
On a different note, I found the breakout rooms to be often small. I think there were only a couple of rooms
that could accommodate more than 500 people, which is a fairly small allowance for 10k attendees. I realized
with frustration that the more interesting talks were immediately fully booked, with people waiting in line
some 45 minutes before the session time. Because of this, I missed a few important sessions that I ll
hopefully watch online later.
Finally, on a more technical side, I ve learned many things, that instead of grouping by session I ll group
by topic, given how some subjects were mentioned in several talks.
On gitops and CI/CD pipelines
Most of the mentions went to
FluxCD and
ArgoCD. At
that point there were no doubts that gitops was a mature approach and both flux and argoCD could do an
excellent job. ArgoCD seemed a bit more over-engineered to be a more general purpose CD pipeline, and flux
felt a bit more tailored for simpler gitops setups. I discovered that both have nice web user interfaces that
I wasn t previously familiar with.
However, in two different talks I got the impression that the initial setup of them was simple, but migrating
your current workflow to gitops could result in a bumpy ride. This is, the challenge is not deploying
flux/argo itself, but moving everything into a state that both humans and flux/argo can understand. I also
saw some curious mentions to the config drifts that can happen in some cases, even if the goal of gitops is
precisely for that to never happen. Such mentions were usually accompanied by some hints on how to operate
the situation by hand.
Worth mentioning, I missed any practical information about one of the key pieces to this whole gitops story:
building container images. Most of the showcased scenarios were using pre-built container images, so in that
sense they were simple. Building and pushing to an image registry is one of the two key points we would need
to solve in Toolforge Kubernetes if adopting gitops.
In general, even if gitops were already in our radar for
Toolforge Kubernetes,
I think it climbed a few steps in my priority list after the conference.
Another learning was this site:
https://opengitops.dev/.

On etcd, performance and resource management
I attended a talk focused on etcd performance tuning that was very encouraging. They were basically talking
about the
exact
same problems we
have had in Toolforge Kubernetes, like api-server and etcd failure modes, and how sensitive etcd is to
disk
latency, IO pressure and network throughput. Even though
Toolforge Kubernetes scale is small compared to other Kubernetes deployments out there, I found it very
interesting to see other s approaches to the same set of challenges.
I learned how most Kubernetes components and apps can overload the api-server. Because even the api-server
talks to itself. Simple things like
kubectl may have a completely different impact on the API depending on
usage, for example when listing the whole list of objects (very expensive) vs a single object.
The conclusion was to try avoiding hitting the api-server with LIST calls, and use ResourceVersion which
avoids full-dumps from etcd (which, by the way, is the default when using bare
kubectl get calls). I
already knew some of this, and for example the
jobs-framework-emailer was already making use of this
ResourceVersion functionality.
There have been a lot of improvements in the performance side of Kubernetes in recent times, or more
specifically, in how resources are managed and used by the system. I saw a review of resource management from
the perspective of the container runtime and kubelet, and plans to support fancy things like topology-aware
scheduling decisions and dynamic resource claims (changing the pod resource claims without
re-defining/re-starting the pods).
On cluster management, bootstrapping and multi-tenancy
I attended a couple of talks that mentioned kubeadm, and one in particular was from the maintainers
themselves. This was of interest to me because as of today
we use it for
Toolforge. They shared all
the latest developments and improvements, and the plans and roadmap for the future, with a special mention to
something they called kubeadm operator , apparently capable of auto-upgrading the cluster, auto-renewing
certificates and such.
I also saw a comparison between the different cluster bootstrappers, which to me confirmed that kubeadm was
the best, from the point of view of being a well established and well-known workflow, plus having a very
active contributor base. The kubeadm developers invited the audience to submit feature requests,
so I did.
The different talks confirmed that the basic unit for multi-tenancy in kubernetes is the namespace. Any
serious multi-tenant usage should leverage this. There were some ongoing conversations, in official sessions
and in the hallway, about the right tool to implement K8s-whitin-K8s, and
vcluster
was mentioned enough times for me to be convinced it was the right candidate. This was despite of my impression
that multiclusters / multicloud are regarded as hard topics in the general community. I definitely would like to play
with it sometime down the road.
On networking
I attended a couple of basic sessions that served really well to understand how Kubernetes instrumented the
network to achieve its goal. The conference program had sessions to cover topics ranging from network
debugging recommendations, CNI implementations, to IPv6 support. Also, one of the keynote sessions had a
reference to how kube-proxy is not able to perform NAT for SIP connections, which is interesting because I
believe Netfilter Conntrack could do it if properly configured. One of the conclusions on the CNI front was
that Calico has a massive community adoption (in Netfilter mode), which is reassuring, especially considering
it is
the one we use for Toolforge Kubernetes.

On jobs
I attended a couple of talks that were related to HPC/grid-like usages of Kubernetes. I was truly impressed
by some folks out there who were using Kubernetes Jobs on massive scales, such as to train machine learning
models and other fancy AI projects.
It is acknowledged in the community that the early implementation of things like Jobs and CronJobs had some
limitations that are now gone, or at least greatly improved. Some new functionalities have been added as
well. Indexed Jobs, for example, enables each Job to have a number (index) and process a chunk of a larger
batch of data based on that index. It would allow for full grid-like features like sequential (or again,
indexed) processing, coordination between Job and more graceful Job restarts. My first reaction was: Is that
something we would like to enable in
Toolforge Jobs Framework?
On policy and security
A surprisingly good amount of sessions covered interesting topics related to policy and security. It was nice
to learn two realities:
- kubernetes is capable of doing pretty much anything security-wise and create
greatly secured environments.
- it does not by default. The defaults are not security-strict on purpose.
It kind of made sense to me: Kubernetes was used for a wide range of use cases, and developers didn t know
beforehand to which particular setup they should accommodate the default security levels.
One session in particular covered the most basic security features that should be enabled for any Kubernetes
system that would get exposed to random end users. In my opinion, the Toolforge Kubernetes setup was already
doing a good job in that regard. To my joy, some sessions referred to the Pod Security Admission mechanism,
which is one of the key security features we re about to adopt (when migrating away from
Pod Security Policy).
I also learned a bit more about Secret resources, their current implementation and how to leverage a
combo of CSI and RBAC for a more secure usage of external secrets.
Finally, one of the major takeaways from the conference was learning about
kyverno and
kubeaudit. I was previously aware of the
OPA Gatekeeper. From the several demos I saw, it
was to me that kyverno should help us make Toolforge Kubernetes more sustainable by replacing all of our
custom admission controllers
with it. I already opened a ticket to
track this idea, which I ll be
proposing to my team soon.
Final notes
In general, I believe I learned many things, and perhaps even more importantly I re-learned some stuff I had
forgotten because of lack of daily exposure. I m really happy that the cloud native way of thinking was
reinforced in me, which I still need because most of my muscle memory to approach systems architecture and
engineering is from the old pre-cloud days.
List of sessions I attended on the first day:
- Keynote
- Node Resource Management: The Big Picture - Sascha Grunert & Swati Sehgal, Red Hat; Alexander Kanevskiy, Intel; Evan Lezar, NVIDIA; David Porter, Google.
- How We Securely Scaled Multi-Tenancy with VCluster, Crossplane, and Argo CD - Ilia Medvedev & Kostis Kapelonis, Codefresh. (Couldn t really attend, room full)
- Flux Beyond Git: Harnessing the Power of OCI - Stefan Prodan & Hidde Beydals, Weaveworks. (Couldn t really attend, room full)
- Tutorial: Measure Twice, Cut Once: Dive Into Network Foundations the Right Way! - Marino Wijay & Jason Skrzypek, Solo.io
- Argo CD Core - A Pure GitOps Agent for Kubernetes - Alexander Matyushentsev, Akuity & Leonardo Luz Almeida, Intuit
- Kubeadm Deep Dive - Rohit Anand, NEC & Paco Xu, Dao
- Cloud Operate Multi-Tenancy Service Mesh with ArgoCD in Production - Lin Sun, Solo.io & Faseela K, Ericsson Software Technology
List of sessions I attended on the second day:
List of sessions I attended on third day:
- Keynote
- Prevent Embarrassing Cluster Takeovers with This One Simple Trick! - Daniele de Araujo dos Santos & Shane Lawrence, Shopify
- Hacking and Defending Kubernetes Clusters: We ll Do It LIVE!!! - Fabian Kammel & James Cleverley-Prance, ControlPlane
- Painless Multi-Cloud to the Edge Powered by NATS & Kubernetes - Tomasz Pietrek & David Gee, Synadia
- Demystifing IPv6 Kubernetes - Antonio Jose Ojea Garcia, Google & Fernando Gont, Yalo
- Open Policy Agent. (OPA) Intro & Deep Dive - Charlie Egan, Styra, Inc. (Couldn t really attend, room full)
- Practical Challenges with Pod Security Admission - V K rbes & Christian Schlotter, VMware
- Enabling HPC and ML Workloads with the Latest Kubernetes Job Features - Micha Wo niak, Google & Vanessa Sochat, Lawrence Livermore National Laboratory
- Can You Keep a Secret? on Secret Management in Kubernetes - Liav Yona & Gal Cohen, Firefly
The videos have been
published on Youtube.

 Daniel Knowles Carmageddon: How Cars Make Life Worse and What to
Do About It is an entertaining, lucid, and well-written manifesto
(to borrow a term from the author) aiming to get us all thinking a bit
more about what cars do to society, and how to move on to a better
outcome for all.
The book alternates between historical context and background, lived
experience (as the author is a foreign correspondent who had the
opportunity to travel), and researched content. It is refreshingly free
of formalities (no endless footnotes or endnotes with references, though
I would have liked occassional references but hey we all went to school
long enough to do a bit of research given a pointer or two). I learned
or relearned a few things as I was for example somewhat unaware of the
air pollution (micro-particle) impact stemming from tires and brake
abrasions for which electronic vehicles do zilch, and for which the
auto-obesity of ever larger and heavier cars is making things
much worse. And some terms (even when re-used by Knowles) are clever
such bionic duckweed. But now you need to read the book to
catch up on it.
Overall, the book argues its case rather well. The author brings
sufficient evidence to make the formal guilty charge quite convincing.
It is also recent having come out just months ago, making current
figures even more relevant.
I forget the exact circumstance but I think I came across the author
in the context of our joint obsession with both Chicago and cycling (as
there may have been a link from a related social media post) and/or the
fact that I followed some of his colleagues at The Economist on
social media. Either way, the number of Chicago and MidWest references
made for some additional fun when reading the book over a the last few
days. And for me another highlight was the ode to Tokyo which I
wholeheartedly agree with: on my second trip to Japan I spent a spare
day cycling across the city as the AirBnB host kindly gave me access to
his bicycles. Great weather, polite drivers, moderate traffic, and just
wicked good infrastructure made me wonder why I did not see more
cyclists.
I have little to criticize beyond the lack of any references. The
repeated insistence on reminding us that Knowles comes from Birmingham
gets a little old by the fifth or sixth repetition. It is all a wee bit
anglo- or UK-centric. It obviously has a bit on France, Paris,
and all the recent success of Anne Hidalgo (who, when I was in graduate
school in France, was still a TV person rather than the very successful
mayor she is now) but then does not mention the immense (and well known)
success of the French train system which lead to a recent dictum to no
longer allow intra-Frace air travel if train rides of under 2 1/2 hours
are available which is rather remarkable. (Though in fairness that may
have been enacted once the book was finished.)
Lastly, the book appears to have a
few sections available via Google Books. My copy will good back from
one near-west suburban library to the neighbouring one.
Overall a strong recommendation for a very good and timely book.
Daniel Knowles Carmageddon: How Cars Make Life Worse and What to
Do About It is an entertaining, lucid, and well-written manifesto
(to borrow a term from the author) aiming to get us all thinking a bit
more about what cars do to society, and how to move on to a better
outcome for all.
The book alternates between historical context and background, lived
experience (as the author is a foreign correspondent who had the
opportunity to travel), and researched content. It is refreshingly free
of formalities (no endless footnotes or endnotes with references, though
I would have liked occassional references but hey we all went to school
long enough to do a bit of research given a pointer or two). I learned
or relearned a few things as I was for example somewhat unaware of the
air pollution (micro-particle) impact stemming from tires and brake
abrasions for which electronic vehicles do zilch, and for which the
auto-obesity of ever larger and heavier cars is making things
much worse. And some terms (even when re-used by Knowles) are clever
such bionic duckweed. But now you need to read the book to
catch up on it.
Overall, the book argues its case rather well. The author brings
sufficient evidence to make the formal guilty charge quite convincing.
It is also recent having come out just months ago, making current
figures even more relevant.
I forget the exact circumstance but I think I came across the author
in the context of our joint obsession with both Chicago and cycling (as
there may have been a link from a related social media post) and/or the
fact that I followed some of his colleagues at The Economist on
social media. Either way, the number of Chicago and MidWest references
made for some additional fun when reading the book over a the last few
days. And for me another highlight was the ode to Tokyo which I
wholeheartedly agree with: on my second trip to Japan I spent a spare
day cycling across the city as the AirBnB host kindly gave me access to
his bicycles. Great weather, polite drivers, moderate traffic, and just
wicked good infrastructure made me wonder why I did not see more
cyclists.
I have little to criticize beyond the lack of any references. The
repeated insistence on reminding us that Knowles comes from Birmingham
gets a little old by the fifth or sixth repetition. It is all a wee bit
anglo- or UK-centric. It obviously has a bit on France, Paris,
and all the recent success of Anne Hidalgo (who, when I was in graduate
school in France, was still a TV person rather than the very successful
mayor she is now) but then does not mention the immense (and well known)
success of the French train system which lead to a recent dictum to no
longer allow intra-Frace air travel if train rides of under 2 1/2 hours
are available which is rather remarkable. (Though in fairness that may
have been enacted once the book was finished.)
Lastly, the book appears to have a
few sections available via Google Books. My copy will good back from
one near-west suburban library to the neighbouring one.
Overall a strong recommendation for a very good and timely book.
 Debian Celebrates 30 years!
We celebrated our
Debian Celebrates 30 years!
We celebrated our 






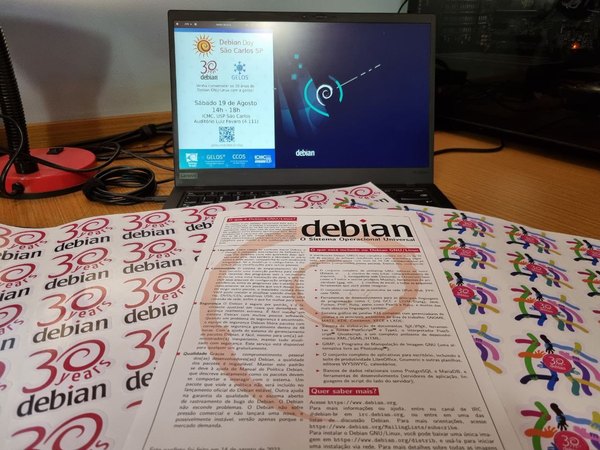














 Em 2023 o tradicional
Em 2023 o tradicional 












 Installing a laptop with the shiny new Debian Bookworm release finds a few interesting things broken that I probably had fixed in the past already on the old laptop.
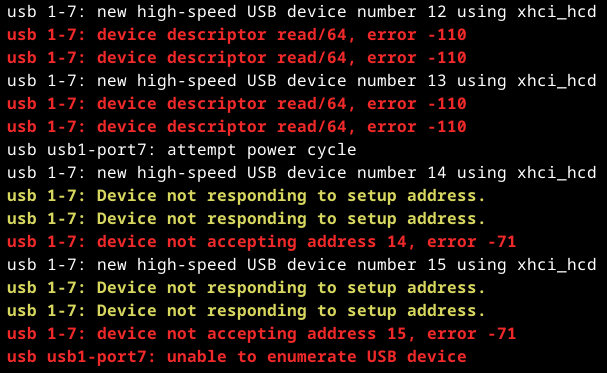
One, that was increadibly unintuitive to fix, was lots of applications (like xfce4-terminal or Telegram) opening links in Chromium despite Firefox being set as the preferred webbrowser everywhere.
Installing a laptop with the shiny new Debian Bookworm release finds a few interesting things broken that I probably had fixed in the past already on the old laptop.
One, that was increadibly unintuitive to fix, was lots of applications (like xfce4-terminal or Telegram) opening links in Chromium despite Firefox being set as the preferred webbrowser everywhere.
 Googleing these
Googleing these 
 After my father passed away, I brought home most of the personal items
he had, both at home and at his office. Among many, many (many, many,
many) other things, I brought two of his personal treasures: His photo
collection and a box with the 8mm movies he shot approximately between
1956 and 1989, when he was forced into modernity and got a portable
videocassette recorder.
I have talked with several friends, as I really want to get it all in
a digital format, and while I ve been making slow but steady advances
scanning the photo reels, I was particularly dismayed (even though it
was most expected most personal electronic devices aren t meant to
last over 50 years) to find out the 8mm projector was no longer in
working conditions; the lamp and the fans work, but the spindles won t
spin. Of course, it is quite likely it is easy to fix, but it is
beyond my tinkering abilities and finding photographic equipment
repair shops is no longer easy. Anyway, even if I got it fixed,
filming a movie from a screen, even with a decent camera, is a lousy
way to get it digitized.
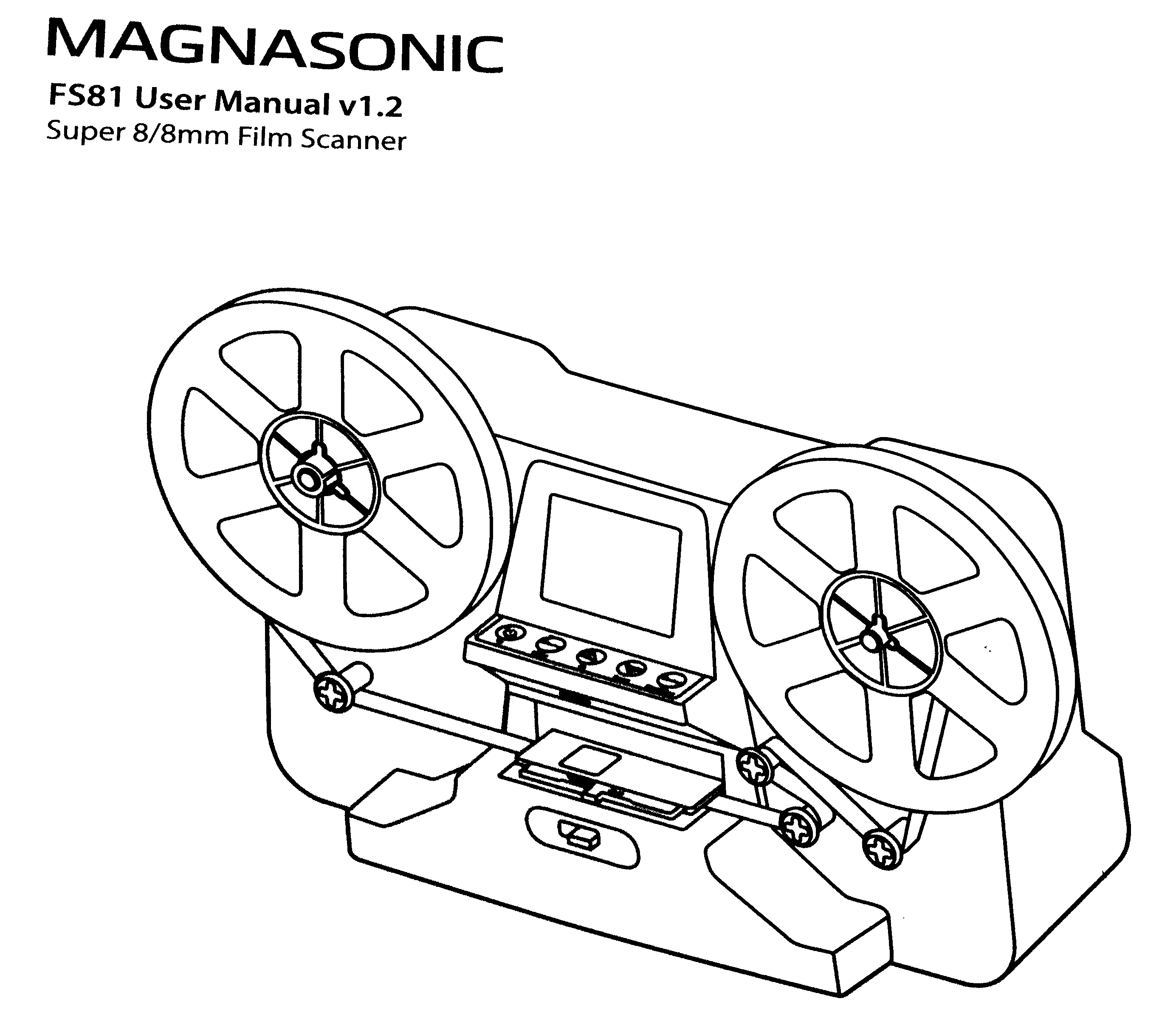
But almost by mere chance, I got in contact with my cousin Daniel, ho
came to Mexico to visit his parents, and had precisely brought with
him a 8mm/Super8 movie scanner! It is a much simpler piece of
equipment than I had expected, and while it does present some minor
glitches (i.e. the vertical framing slightly loses alignment over the
course of a medium-length film scanning session, and no adjustment is
possible while the scan is ongoing), this is something
that can be decently fixed in post-processing, and a scanning session
can be split with no ill effects. Anyway, it is quite uncommon a
mid-length (5min) film can be done without interrupting i.e. to join a
splice, mostly given my father didn t just film, but also edited a lot
(this is, it s not just family pictures, but all different kinds of
fiction and documentary work he did).
After my father passed away, I brought home most of the personal items
he had, both at home and at his office. Among many, many (many, many,
many) other things, I brought two of his personal treasures: His photo
collection and a box with the 8mm movies he shot approximately between
1956 and 1989, when he was forced into modernity and got a portable
videocassette recorder.
I have talked with several friends, as I really want to get it all in
a digital format, and while I ve been making slow but steady advances
scanning the photo reels, I was particularly dismayed (even though it
was most expected most personal electronic devices aren t meant to
last over 50 years) to find out the 8mm projector was no longer in
working conditions; the lamp and the fans work, but the spindles won t
spin. Of course, it is quite likely it is easy to fix, but it is
beyond my tinkering abilities and finding photographic equipment
repair shops is no longer easy. Anyway, even if I got it fixed,
filming a movie from a screen, even with a decent camera, is a lousy
way to get it digitized.
But almost by mere chance, I got in contact with my cousin Daniel, ho
came to Mexico to visit his parents, and had precisely brought with
him a 8mm/Super8 movie scanner! It is a much simpler piece of
equipment than I had expected, and while it does present some minor
glitches (i.e. the vertical framing slightly loses alignment over the
course of a medium-length film scanning session, and no adjustment is
possible while the scan is ongoing), this is something
that can be decently fixed in post-processing, and a scanning session
can be split with no ill effects. Anyway, it is quite uncommon a
mid-length (5min) film can be done without interrupting i.e. to join a
splice, mostly given my father didn t just film, but also edited a lot
(this is, it s not just family pictures, but all different kinds of
fiction and documentary work he did).


 I wrote the
I wrote the  Wrong sort of shim, but canned language bindings would be handy
Wrong sort of shim, but canned language bindings would be handy
 This is what I imagine it looks like inside these libraries
This is what I imagine it looks like inside these libraries
 Yesterday, the UBports core developer team released Ubuntu Touch Focal OTA-1
(In fact, Raoul, Marius and I were in a conference call when Marius froze and said: the PR team already posted the release blog post; the post is out, but we haven't released yet... ahhhh... panic... Shall I?, Marius said, and we said: GO!!! This is why the release occurred in public five hours ahead of schedule. OMG.)
For all the details, please study:
Yesterday, the UBports core developer team released Ubuntu Touch Focal OTA-1
(In fact, Raoul, Marius and I were in a conference call when Marius froze and said: the PR team already posted the release blog post; the post is out, but we haven't released yet... ahhhh... panic... Shall I?, Marius said, and we said: GO!!! This is why the release occurred in public five hours ahead of schedule. OMG.)
For all the details, please study: This can - for permanent use - be put into a config file, e.g.
This can - for permanent use - be put into a config file, e.g.  Update on 2023-03-23: thanks to Daniel Roschka for mentioning the
Update on 2023-03-23: thanks to Daniel Roschka for mentioning the  Apparently neither GNOME nor KDE have apps that are sufficient to produce such content. Wtf folks.
P.S.: Just checked the
Apparently neither GNOME nor KDE have apps that are sufficient to produce such content. Wtf folks.
P.S.: Just checked the  Pdf is hard.
Pdf is hard.
{kind=link}